JavaScript 知识总结
简介
定义:JavaScript 一种直译式脚本语言,是一种动态类型、弱类型、基于原型的语言。
产生原因:网页没有复杂交互行为。
语法
变量类型
- number
- string
- boolean
- object
- function
- null
- undefined
关键字
-
流程控制
- return
- continue
- break
- do
- while
- for
- if
- else
- switch
- case
-
定义
- var :定义变量
- let : 不可重复声明、块级作用域(ES6+)
- const : 不可重复声明、块级作用域(ES6+)
- function
- new
-
异常处理
- try :测试代码块的错误
- catch:处理错误
- finally
- throw :创建自定义错误
-
类型判断
- typeof
- instanceof
-
其他
- this
- in : 与 for 一起使用用于遍历对象的属性名或判断某个对象是否具有某个属性
- delete : 删除对象的某个属性,只能删除自身定义的公有属性,即"this.属性名"定义的属性,而不能删除私有属性或通过 proptotype 定义的公有属性(已实践)。此外可删除直接在对象上添加的属性,如
var a = new Object();a.name = "name"; delete a.name; - with : 引用一个对象,使访问属性与方法更加方便(只能访问与修改属性,不能增加属性与方法)
运算符
- 数学运算符 : +,-,*,/,%
- 比较运算符 : >,<,==,!=,>=,<=,===,!==
- 逻辑运算符 : &&,||,!
- 位操作符 : ^,~,&,|,«,»,»>
函数的定义
- 正常方式
function mysum(num1,num2){return num1+num2;} - 直接量/匿名方式
var mysum = function(num1,num2){return num1+num2;} - 构造器方式
new Function("num1","num2","return num1+num2;") - 箭头函数(ES6)
常用对象
内建对象
- Math
- Date
- getTime() : 获取毫秒值
- String
- length : 字符串的长度
- indexOf() : 检索字符串。
- substr() : 从起始索引号提取字符串中指定数目的字符。
- split() : 把字符串分割为字符串数组。
- Array
- length : 设置或返回数组中元素的数目。
- join() : 把数组的所有元素放入一个字符串。元素通过指定的分隔符进行分隔。
- push() : 向数组的末尾添加一个或更多元素,并返回新的长度。
- splice() : 删除元素,并返回删除元素
- RegExp
- 修饰符
- i : 执行对大小写不敏感的匹配。
- g : 执行全局匹配(查找所有匹配而非在找到第一个匹配后停止)。
- 中括号
- [abc] : 查找方括号之间的任何字符。
- [^abc] : 查找任何不在方括号之间的字符。
- [0-9] : 查找任何从 0 至 9 的数字。
- [a-z] : 查找任何从小写 a 到小写 z 的字符。
- [A-Z] : 查找任何从大写 A 到大写 Z 的字符。
- [A-z] : 查找任何从大写 A 到小写 z 的字符。
- 元字符
- . : 查找单个字符,除了换行和行结束符。
- \w : 查找任意一个字母、数字或下划线字符。
- \W : 查找非\w 字符。
- \d : 查找数字。
- \D : 查找非数字字符。
- \s : 查找空白字符。
- \S : 查找非空白字符。
- \b : 匹配单词边界。
- \B : 匹配非单词边界。
- 量词
- n+ : 匹配任何包含至少一个 n 的字符串。
- n* : 匹配任何包含零个或多个 n 的字符串。
- n? : 匹配任何包含零个或一个 n 的字符串。
- n{X} : 匹配包含 X 个 n 的序列的字符串。
- n{X,Y} : 匹配包含 X 至 Y 个 n 的序列的字符串。
- n{X,} : 匹配包含至少 X 个 n 的序列的字符串。
- n$ : 匹配任何结尾为 n 的字符串。
- ^n : 匹配任何开头为 n 的字符串。
- ?=n : 匹配任何其后紧接指定字符串 n 的字符串。
- ?!n : 匹配任何其后没有紧接指定字符串 n 的字符串。
- 修饰符
HTML DOM 对象
- document
- document.getElementById() : 返回对拥有指定 id 的第一个对象的引用。
- element
- id : 设置或者返回元素的 id。
- className : 设置或返回元素的 class 属性
- style : 设置或返回元素的样式属性
- title : 设置或返回元素的 title 属性
- getAttribute() : 返回指定元素的属性值
- setAttribute() : 设置或者改变指定属性并指定值
- innerHTML : 设置或者返回元素的内容
- outerHTML : 设置或返回元素的全部内容包括标签部分
- clientHeight : 在页面上返回内容的可视高度(不包括边框,边距或滚动条)
- clientWidth : 在页面上返回内容的可视宽度(不包括边框,边距或滚动条)
- scrollHeight : 返回整个元素的高度(包括带滚动条的隐蔽的地方)
- scrollTop : 返回滚动的高度
HTML BOM 对象
- window
- alert() : 显示带有一段消息和一个确认按钮的警告框。
- setInterval(函数,毫秒数) : 每隔一段时间执行函数
- clearInterval(定时器对象) : 结束定时器
- setTimeout(函数,毫秒数) : 一段时间后执行函数
- clearTimeout(超时器对象) : 结束超时器
- location
- href : 返回完整的 URL(直接使用 location 就相当于调用这个属性)
- history
- back() : 加载 history 列表中的前一个 URL
- forward() : 加载 history 列表中的下一个 URL
- go() : 加载 history 列表中的某个具体页面
- screen
- availHeight : 返回屏幕的高度(不包括 Windows 任务栏)
- availWidth : 返回屏幕的宽度(不包括 Windows 任务栏)
- height : 返回屏幕的总高度
- width : 返回屏幕的总宽度
- navigator
- userAgent : 返回由客户机发送服务器的 user-agent 头部的值
AJAX 对象
- ActiveXObject
- XMLHttpRequest
常用全局方法
- parseInt() : 字符串转换整型
- eval() : 执行字符串表达式,如果是变量需要加上括号:eval("("+var+")")
- encodeURI(string):对 URI 字符串进行 UTF-8 的编码
扩展
ES5 数组新增方法
一、前言-索引
ES5 中新增的不少东西,了解之对我们写 JavaScript 会有不少帮助,比如数组这块,我们可能就不需要去有板有眼地for循环了。
ES5 中新增了写数组方法,如下:
- forEach (js v1.6)
- map (js v1.6)
- filter (js v1.6)
- some (js v1.6)
- every (js v1.6)
- indexOf (js v1.6)
- lastIndexOf (js v1.6)
- reduce (js v1.8)
- reduceRight (js v1.8)
浏览器支持
- Opera 11+
- Firefox 3.6+
- Safari 5+
- Chrome 8+
- Internet Explorer 9+
对于让人失望很多次的 IE6-IE8 浏览器,Array 原型扩展可以实现以上全部功能,例如forEach方法:
|
|
二、一个一个来
forEach
forEach 是 Array 新方法中最基本的一个,就是遍历,循环。例如下面这个例子:
|
|
等同于下面这个传统的for循环:
|
|
Array 在 ES5 新增的方法中,参数都是function类型,默认有传参,这些参数分别是?见下面:
|
|

显而易见,forEach方法中的function回调支持 3 个参数,第 1 个是遍历的数组内容;第 2 个是对应的数组索引,第 3 个是数组本身。
因此,我们有:
|
|
对比 jQuery 中的$.each方法:
|
|
会发现,第 1 个和第 2 个参数正好是相反的,大家要注意了,不要记错了。后面类似的方法,例如$.map也是如此。
现在,我们就可以使用forEach卖弄一个稍显完整的例子了,数组求和:
|
|
再下面,更进一步,forEach除了接受一个必须的回调函数参数,还可以接受一个可选的上下文参数(改变回调函数里面的this指向)(第 2 个参数)。
|
|
例子更能说明一切:
|
|
如果这第 2 个可选参数不指定,则使用全局对象代替(在浏览器是为window),严格模式下甚至是undefined.
另外,forEach 不会遍历纯粹“占着官位吃空饷”的元素的,例如下面这个例子:
|
|
综上全部规则,我们就可以对 IE6-IE8 进行仿真扩展了,如下代码:
|
|
现在拿上面“张含韵”的例子测下我们扩展的forEach方法,您可能狠狠地点击这里:兼容处理的 forEach 方法 demo
例如 IE7 浏览器下:

map
这里的 map 不是“地图”的意思,而是指“映射”。
|
|
基本用法跟 forEach 方法类似:
|
|
callback的参数也类似:
|
|
map方法的作用不难理解,“映射”嘛,也就是原数组被“映射”成对应新数组。下面这个例子是数值项求平方:
|
|
callback需要有return值,如果没有,就像下面这样:
|
|
结果如下图,可以看到,数组所有项都被映射成了undefined:

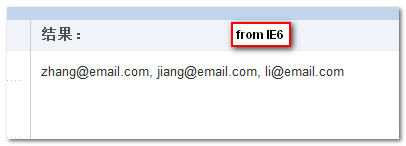
在实际使用的时候,我们可以利用map方法方便获得对象数组中的特定属性值们。例如下面这个例子(之后的兼容 demo 也是该例子):
|
|
Array.prototype扩展可以让 IE6-IE8 浏览器也支持map方法:
|
|
您可以狠狠地点击这里:兼容 map 方法测试 demo
结果显示如下图,IE6 浏览器:
filter
filter 为“过滤”、“筛选”之意。指数组过滤后,返回过滤后的新数组。用法跟 map 极为相似:
|
|
filter的callback函数需要返回布尔值true或false. 如果为true则表示,恭喜你,通过啦!如果为false, 只能高歌“我只能无情地将你抛弃……”)。
可能会疑问,一定要是Boolean值吗?我们可以简单测试下嘛,如下:
|
|
有此可见,返回值只要是弱等于== true/false就可以了,而非非得返回 === true/false.
因此,我们在为低版本浏览器扩展时候,无需关心是否返回值是否是纯粹布尔值(见下黑色代码部分):
|
|
接着上面map筛选邮件的例子,您可以狠狠地点击这里:兼容处理后 filter 方法测试 demo
主要测试代码为:
|
|

实际上,存在一些语法糖可以实现
map+filter的效果,被称之为“数组简约式(Array comprehensions)”。目前,仅 FireFox 浏览器可以实现,展示下又不会怀孕:
1 2 3var zhangEmails = [user.email for each (user in users) if (/^zhang/.test(user.email)) ]; console.log(zhangEmails); // [zhang@email.com]

some
some 意指“某些”,指是否“某些项”合乎条件。与下面的 every 算是好基友,every 表示是否“每一项”都要靠谱。用法如下:
|
|
例如下面的简单使用:
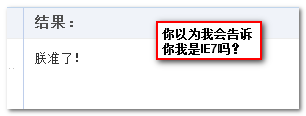
|
|
结果弹出了“朕准了”文字。 some要求至少有 1 个值让callback返回true就可以了。显然,8 > 7,因此scores.some(higherThanCurrent)值为true.
我们自然可以使用forEach进行判断,不过,相比some, 不足在于,some只有有true即返回不再执行了。
IE6-IE8 扩展如下:
|
|
于是,我们就有了“朕准了”的 demo,您可以狠狠地点击这里:兼容处理后的 some 方法 demo
every
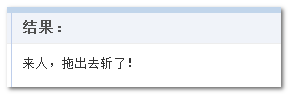
跟 some 的基友关系已经是公开的秘密了,同样是返回 Boolean 值,不过,every 需要每一个妃子都要让朕满意,否则——“来人,给我拖出去砍了!”
IE6-IE8 扩展(与some相比就是true和false调换一下):
|
|
还是那个朕的例子,您可以狠狠地点击这里:是否 every 妃子让朕满意 demo
|
|
结果是:
indexOf
indexOf 方法在字符串中自古就有,
|
|
。数组这里的 indexOf 方法与之类似。
|
|
返回整数索引值,如果没有匹配(严格匹配),返回-1. fromIndex可选,表示从这个位置开始搜索,若缺省或格式不合要求,使用默认值0,我在 FireFox 下测试,发现使用字符串数值也是可以的,例如"3"和3都可以。
|
|
兼容处理如下:
|
|
一个路子下来的,显然,轮到 demo 了,您可以狠狠地点击这里:兼容处理后 indexOf 方法测试 demo
下图为 ietester IE6 下的截图:

lastIndexOf
lastIndexOf 方法与 indexOf 方法类似:
|
|
只是lastIndexOf是从字符串的末尾开始查找,而不是从开头。还有一个不同就是fromIndex的默认值是array.length - 1而不是0.
IE6 等浏览器如下折腾:
|
|
于是,则有:
|
|
懒得截图了,结果查看可狠狠地点击这里:lastIndexOf 测试 demo
reduce
reduce 是 JavaScript 1.8 中才引入的,中文意思为“减少”、“约简”。不过,从功能来看,我个人是无法与“减少”这种含义联系起来的,反而更接近于“迭代”、“递归(recursion)”,擦,因为单词这么接近,不会是 ECMA-262 5th 制定者笔误写错了吧~~
此方法相比上面的方法都复杂,用法如下:
|
|
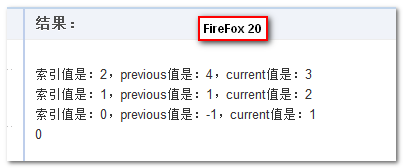
callback函数接受 4 个参数:之前值、当前值、索引值以及数组本身。initialValue参数可选,表示初始值。若指定,则当作最初使用的previous值;如果缺省,则使用数组的第一个元素作为previous初始值,同时current往后排一位,相比有initialValue值少一次迭代。
|
|
说明:
- 因为
initialValue不存在,因此一开始的previous值等于数组的第一个元素。 - 从而
current值在第一次调用的时候就是2. - 最后两个参数为索引值
index以及数组本身array.
以下为循环执行过程:
|
|
有了reduce,我们可以轻松实现二维数组的扁平化:
|
|
兼容处理 IE6-IE8:
|
|
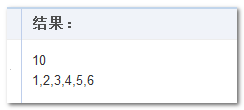
然后,测试整合,demo 演示,您可以狠狠地点击这里:兼容 IE6 的 reduce 方法测试 demo
IE6 浏览器下结果如下图:
reduceRight
reduceRight 跟 reduce 相比,用法类似:
|
|
实现上差异在于reduceRight是从数组的末尾开始实现。看下面这个例子:
|
|
结果0是如何得到的呢?
我们一步一步查看循环执行:
|
|
为使低版本浏览器支持此方法,您可以添加如下代码:
|
|
您可以狠狠地点击这里:reduceRight 简单使用 demo
对比 FireFox 浏览器和 IE7 浏览器下的结果:

三、更进一步的应用
我们还可以将上面这些数组方法应用在其他对象上。
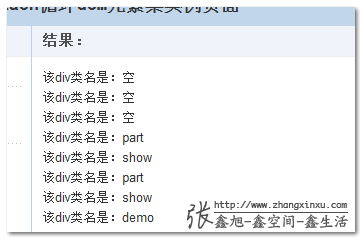
例如,我们使用 forEach 遍历 DOM 元素。
|
|
可以输出页面所有div的类名,您可以狠狠地点击这里:Array 新方法 forEach 遍历 DOM demo
结果如下,IE6 下,demo 结果:
等很多其他类数组应用。
四、最后一点点了
本文为低版本 IE 扩展的 Array 方法我都合并到一个 JS 中了,您可以轻轻的右键这里或下载或查看:es5-array.js
以上所有未 IE 扩展的方法都是自己根据理解写的,虽然多番测试,难免还会有细节遗漏的,欢迎指出来。
ES6
let 和 const
let 命令
基本用法
ES6 新增了let命令,用来声明变量。它的用法类似于var,但是所声明的变量,只在let命令所在的代码块内有效。
|
|
上面代码在代码块之中,分别用let和var声明了两个变量。然后在代码块之外调用这两个变量,结果let声明的变量报错,var声明的变量返回了正确的值。这表明,let声明的变量只在它所在的代码块有效。
for循环的计数器,就很合适使用let命令。
|
|
上面代码中,计数器i只在for循环体内有效,在循环体外引用就会报错。
下面的代码如果使用var,最后输出的是10。
|
|
上面代码中,变量i是var命令声明的,在全局范围内都有效,所以全局只有一个变量i。每一次循环,变量i的值都会发生改变,而循环内被赋给数组a的函数内部的console.log(i),里面的i指向的就是全局的i。也就是说,所有数组a的成员里面的i,指向的都是同一个i,导致运行时输出的是最后一轮的i的值,也就是 10。
如果使用let,声明的变量仅在块级作用域内有效,最后输出的是 6。
|
|
上面代码中,变量i是let声明的,当前的i只在本轮循环有效,所以每一次循环的i其实都是一个新的变量,所以最后输出的是6。你可能会问,如果每一轮循环的变量i都是重新声明的,那它怎么知道上一轮循环的值,从而计算出本轮循环的值?这是因为 JavaScript 引擎内部会记住上一轮循环的值,初始化本轮的变量i时,就在上一轮循环的基础上进行计算。
另外,for循环还有一个特别之处,就是设置循环变量的那部分是一个父作用域,而循环体内部是一个单独的子作用域。
|
|
上面代码正确运行,输出了 3 次abc。这表明函数内部的变量i与循环变量i不在同一个作用域,有各自单独的作用域(同一个作用域不可使用 let 重复声明同一个变量)。
不存在变量提升
var命令会发生“变量提升”现象,即变量可以在声明之前使用,值为undefined。这种现象多多少少是有些奇怪的,按照一般的逻辑,变量应该在声明语句之后才可以使用。
为了纠正这种现象,let命令改变了语法行为,它所声明的变量一定要在声明后使用,否则报错。
|
|
上面代码中,变量foo用var命令声明,会发生变量提升,即脚本开始运行时,变量foo已经存在了,但是没有值,所以会输出undefined。变量bar用let命令声明,不会发生变量提升。这表示在声明它之前,变量bar是不存在的,这时如果用到它,就会抛出一个错误。
暂时性死区
只要块级作用域内存在let命令,它所声明的变量就“绑定”(binding)这个区域,不再受外部的影响。
|
|
上面代码中,存在全局变量tmp,但是块级作用域内let又声明了一个局部变量tmp,导致后者绑定这个块级作用域,所以在let声明变量前,对tmp赋值会报错。
ES6 明确规定,如果区块中存在let和const命令,这个区块对这些命令声明的变量,从一开始就形成了封闭作用域。凡是在声明之前就使用这些变量,就会报错。
总之,在代码块内,使用let命令声明变量之前,该变量都是不可用的。这在语法上,称为“暂时性死区”(temporal dead zone,简称 TDZ)。
|
|
上面代码中,在let命令声明变量tmp之前,都属于变量tmp的“死区”。
“暂时性死区”也意味着typeof不再是一个百分之百安全的操作。
|
|
上面代码中,变量x使用let命令声明,所以在声明之前,都属于x的“死区”,只要用到该变量就会报错。因此,typeof运行时就会抛出一个ReferenceError。
作为比较,如果一个变量根本没有被声明,使用typeof反而不会报错。
|
|
上面代码中,undeclared_variable是一个不存在的变量名,结果返回“undefined”。所以,在没有let之前,typeof运算符是百分之百安全的,永远不会报错。现在这一点不成立了。这样的设计是为了让大家养成良好的编程习惯,变量一定要在声明之后使用,否则就报错。
有些“死区”比较隐蔽,不太容易发现。
|
|
上面代码中,调用bar函数之所以报错(某些实现可能不报错),是因为参数x默认值等于另一个参数y,而此时y还没有声明,属于“死区”。如果y的默认值是x,就不会报错,因为此时x已经声明了。
|
|
另外,下面的代码也会报错,与var的行为不同。
|
|
上面代码报错,也是因为暂时性死区。使用let声明变量时,只要变量在还没有声明完成前使用,就会报错。上面这行就属于这个情况,在变量x的声明语句还没有执行完成前,就去取x的值,导致报错”x 未定义“。
ES6 规定暂时性死区和let、const语句不出现变量提升,主要是为了减少运行时错误,防止在变量声明前就使用这个变量,从而导致意料之外的行为。这样的错误在 ES5 是很常见的,现在有了这种规定,避免此类错误就很容易了。
总之,暂时性死区的本质就是,只要一进入当前作用域,所要使用的变量就已经存在了,但是不可获取,只有等到声明变量的那一行代码出现,才可以获取和使用该变量。
不允许重复声明
let不允许在相同作用域内,重复声明同一个变量。
|
|
因此,不能在函数内部重新声明参数。
|
|
块级作用域
为什么需要块级作用域?
ES5 只有全局作用域和函数作用域,没有块级作用域,这带来很多不合理的场景。
第一种场景,内层变量可能会覆盖外层变量。
|
|
上面代码的原意是,if代码块的外部使用外层的tmp变量,内部使用内层的tmp变量。但是,函数f执行后,输出结果为undefined,原因在于变量提升,导致内层的tmp变量覆盖了外层的tmp变量。
第二种场景,用来计数的循环变量泄露为全局变量。
|
|
上面代码中,变量i只用来控制循环,但是循环结束后,它并没有消失,泄露成了全局变量。
ES6 的块级作用域
let实际上为 JavaScript 新增了块级作用域。
|
|
上面的函数有两个代码块,都声明了变量n,运行后输出 5。这表示外层代码块不受内层代码块的影响。如果两次都使用var定义变量n,最后输出的值才是 10。
ES6 允许块级作用域的任意嵌套。
|
|
上面代码使用了一个五层的块级作用域,每一层都是一个单独的作用域。第四层作用域无法读取第五层作用域的内部变量。
内层作用域可以定义外层作用域的同名变量。
|
|
块级作用域的出现,实际上使得获得广泛应用的匿名立即执行函数表达式(匿名 IIFE)不再必要了。
|
|
块级作用域与函数声明
函数能不能在块级作用域之中声明?这是一个相当令人混淆的问题。
ES5 规定,函数只能在顶层作用域和函数作用域之中声明,不能在块级作用域声明。
|
|
上面两种函数声明,根据 ES5 的规定都是非法的。
但是,浏览器没有遵守这个规定,为了兼容以前的旧代码,还是支持在块级作用域之中声明函数,因此上面两种情况实际都能运行,不会报错。
ES6 引入了块级作用域,明确允许在块级作用域之中声明函数。ES6 规定,块级作用域之中,函数声明语句的行为类似于let,在块级作用域之外不可引用。
|
|
上面代码在 ES5 中运行,会得到“I am inside!”,因为在if内声明的函数f会被提升到函数头部,实际运行的代码如下。
|
|
ES6 就完全不一样了,理论上会得到“I am outside!”。因为块级作用域内声明的函数类似于let,对作用域之外没有影响。但是,如果你真的在 ES6 浏览器中运行一下上面的代码,是会报错的,这是为什么呢?
|
|
上面的代码在 ES6 浏览器中,都会报错。
原来,如果改变了块级作用域内声明的函数的处理规则,显然会对老代码产生很大影响。为了减轻因此产生的不兼容问题,ES6 在附录 B里面规定,浏览器的实现可以不遵守上面的规定,有自己的行为方式。
- 允许在块级作用域内声明函数。
- 函数声明类似于
var,即会提升到全局作用域或函数作用域的头部。 - 同时,函数声明还会提升到所在的块级作用域的头部。
注意,上面三条规则只对 ES6 的浏览器实现有效,其他环境的实现不用遵守,还是将块级作用域的函数声明当作let处理。
根据这三条规则,浏览器的 ES6 环境中,块级作用域内声明的函数,行为类似于var声明的变量。上面的例子实际运行的代码如下。
|
|
考虑到环境导致的行为差异太大,应该避免在块级作用域内声明函数。如果确实需要,也应该写成函数表达式,而不是函数声明语句。
|
|
另外,还有一个需要注意的地方。ES6 的块级作用域必须有大括号,如果没有大括号,JavaScript 引擎就认为不存在块级作用域。
|
|
上面代码中,第一种写法没有大括号,所以不存在块级作用域,而let只能出现在当前作用域的顶层,所以报错。第二种写法有大括号,所以块级作用域成立。
函数声明也是如此,严格模式下,函数只能声明在当前作用域的顶层。
|
|
const 命令
基本用法
const声明一个只读的常量。一旦声明,常量的值就不能改变。
|
|
上面代码表明改变常量的值会报错。
const声明的变量不得改变值,这意味着,const一旦声明变量,就必须立即初始化,不能留到以后赋值。
|
|
上面代码表示,对于const来说,只声明不赋值,就会报错。
const的作用域与let命令相同:只在声明所在的块级作用域内有效。
|
|
const命令声明的常量也是不提升,同样存在暂时性死区,只能在声明的位置后面使用。
|
|
上面代码在常量MAX声明之前就调用,结果报错。
const声明的常量,也与let一样不可重复声明。
|
|
本质
const实际上保证的,并不是变量的值不得改动,而是变量指向的那个内存地址所保存的数据不得改动。对于简单类型的数据(数值、字符串、布尔值),值就保存在变量指向的那个内存地址,因此等同于常量。但对于复合类型的数据(主要是对象和数组),变量指向的内存地址,保存的只是一个指向实际数据的指针,const只能保证这个指针是固定的(即总是指向另一个固定的地址),至于它指向的数据结构是不是可变的,就完全不能控制了。因此,将一个对象声明为常量必须非常小心。
|
|
上面代码中,常量foo储存的是一个地址,这个地址指向一个对象。不可变的只是这个地址,即不能把foo指向另一个地址,但对象本身是可变的,所以依然可以为其添加新属性。
下面是另一个例子。
|
|
上面代码中,常量a是一个数组,这个数组本身是可写的,但是如果将另一个数组赋值给a,就会报错。
如果真的想将对象冻结,应该使用Object.freeze方法。
|
|
上面代码中,常量foo指向一个冻结的对象,所以添加新属性不起作用,严格模式时还会报错。
除了将对象本身冻结,对象的属性也应该冻结。下面是一个将对象彻底冻结的函数。
|
|
ES6 声明变量的六种方法
ES5 只有两种声明变量的方法:var命令和function命令。ES6 除了添加let和const命令,后面章节还会提到,另外两种声明变量的方法:import命令和class命令。所以,ES6 一共有 6 种声明变量的方法。
顶层对象的属性
顶层对象,在浏览器环境指的是window对象,在 Node 指的是global对象。ES5 之中,顶层对象的属性与全局变量是等价的。
|
|
上面代码中,顶层对象的属性赋值与全局变量的赋值,是同一件事。
顶层对象的属性与全局变量挂钩,被认为是 JavaScript 语言最大的设计败笔之一。这样的设计带来了几个很大的问题,首先是没法在编译时就报出变量未声明的错误,只有运行时才能知道(因为全局变量可能是顶层对象的属性创造的,而属性的创造是动态的);其次,程序员很容易不知不觉地就创建了全局变量(比如打字出错);最后,顶层对象的属性是到处可以读写的,这非常不利于模块化编程。另一方面,window对象有实体含义,指的是浏览器的窗口对象,顶层对象是一个有实体含义的对象,也是不合适的。
ES6 为了改变这一点,一方面规定,为了保持兼容性,var命令和function命令声明的全局变量,依旧是顶层对象的属性;另一方面规定,let命令、const命令、class命令声明的全局变量,不属于顶层对象的属性。也就是说,从 ES6 开始,全局变量将逐步与顶层对象的属性脱钩。
|
|
上面代码中,全局变量a由var命令声明,所以它是顶层对象的属性;全局变量b由let命令声明,所以它不是顶层对象的属性,返回undefined。
globalThis 对象
JavaScript 语言存在一个顶层对象,它提供全局环境(即全局作用域),所有代码都是在这个环境中运行。但是,顶层对象在各种实现里面是不统一的。
- 浏览器里面,顶层对象是
window,但 Node 和 Web Worker 没有window。 - 浏览器和 Web Worker 里面,
self也指向顶层对象,但是 Node 没有self。 - Node 里面,顶层对象是
global,但其他环境都不支持。
同一段代码为了能够在各种环境,都能取到顶层对象,现在一般是使用this关键字,但是有局限性。
- 全局环境中,
this会返回顶层对象。但是,Node.js 模块中this返回的是当前模块,ES6 模块中this返回的是undefined。 - 函数里面的
this,如果函数不是作为对象的方法运行,而是单纯作为函数运行,this会指向顶层对象。但是,严格模式下,这时this会返回undefined。 - 不管是严格模式,还是普通模式,
new Function('return this')(),总是会返回全局对象。但是,如果浏览器用了 CSP(Content Security Policy,内容安全策略),那么eval、new Function这些方法都可能无法使用。
综上所述,很难找到一种方法,可以在所有情况下,都取到顶层对象。下面是两种勉强可以使用的方法。
|
|
ES2020 在语言标准的层面,引入globalThis作为顶层对象。也就是说,任何环境下,globalThis都是存在的,都可以从它拿到顶层对象,指向全局环境下的this。
垫片库global-this模拟了这个提案,可以在所有环境拿到globalThis。
解构赋值
数组的解构赋值
基本用法
ES6 允许按照一定模式,从数组和对象中提取值,对变量进行赋值,这被称为解构(Destructuring)。
以前,为变量赋值,只能直接指定值。
|
|
ES6 允许写成下面这样。
|
|
上面代码表示,可以从数组中提取值,按照对应位置,对变量赋值。
本质上,这种写法属于“模式匹配”,只要等号两边的模式相同,左边的变量就会被赋予对应的值。下面是一些使用嵌套数组进行解构的例子。
|
|
如果解构不成功,变量的值就等于undefined。
|
|
以上两种情况都属于解构不成功,foo的值都会等于undefined。
另一种情况是不完全解构,即等号左边的模式,只匹配一部分的等号右边的数组。这种情况下,解构依然可以成功。
|
|
上面两个例子,都属于不完全解构,但是可以成功。
如果等号的右边不是数组(或者严格地说,不是可遍历的结构,参见《Iterator》一章),那么将会报错。
|
|
上面的语句都会报错,因为等号右边的值,要么转为对象以后不具备 Iterator 接口(前五个表达式),要么本身就不具备 Iterator 接口(最后一个表达式)。
对于 Set 结构,也可以使用数组的解构赋值。
|
|
事实上,只要某种数据结构具有 Iterator 接口,都可以采用数组形式的解构赋值。
|
|
上面代码中,fibs是一个 Generator 函数(参见《Generator 函数》一章),原生具有 Iterator 接口。解构赋值会依次从这个接口获取值。
默认值
解构赋值允许指定默认值。
|
|
注意,ES6 内部使用严格相等运算符(===),判断一个位置是否有值。所以,只有当一个数组成员严格等于undefined,默认值才会生效。
|
|
上面代码中,如果一个数组成员是null,默认值就不会生效,因为null不严格等于undefined。
如果默认值是一个表达式,那么这个表达式是惰性求值的,即只有在用到的时候,才会求值。
|
|
上面代码中,因为x能取到值,所以函数f根本不会执行。上面的代码其实等价于下面的代码。
|
|
默认值可以引用解构赋值的其他变量,但该变量必须已经声明。
|
|
上面最后一个表达式之所以会报错,是因为x用y做默认值时,y还没有声明。
对象的解构赋值
简介
解构不仅可以用于数组,还可以用于对象。
|
|
对象的解构与数组有一个重要的不同。数组的元素是按次序排列的,变量的取值由它的位置决定;而对象的属性没有次序,变量必须与属性同名,才能取到正确的值。
|
|
上面代码的第一个例子,等号左边的两个变量的次序,与等号右边两个同名属性的次序不一致,但是对取值完全没有影响。第二个例子的变量没有对应的同名属性,导致取不到值,最后等于undefined。
如果解构失败,变量的值等于undefined。
|
|
上面代码中,等号右边的对象没有foo属性,所以变量foo取不到值,所以等于undefined。
对象的解构赋值,可以很方便地将现有对象的方法,赋值到某个变量。
|
|
上面代码的例一将Math对象的对数、正弦、余弦三个方法,赋值到对应的变量上,使用起来就会方便很多。例二将console.log赋值到log变量。
如果变量名与属性名不一致,必须写成下面这样。
|
|
这实际上说明,对象的解构赋值是下面形式的简写(参见《对象的扩展》一章)。
|
|
也就是说,对象的解构赋值的内部机制,是先找到同名属性,然后再赋给对应的变量。真正被赋值的是后者,而不是前者。
|
|
上面代码中,foo是匹配的模式,baz才是变量。真正被赋值的是变量baz,而不是模式foo。
与数组一样,解构也可以用于嵌套结构的对象。
|
|
注意,这时p是模式,不是变量,因此不会被赋值。如果p也要作为变量赋值,可以写成下面这样。
|
|
下面是另一个例子。
|
|
上面代码有三次解构赋值,分别是对loc、start、line三个属性的解构赋值。注意,最后一次对line属性的解构赋值之中,只有line是变量,loc和start都是模式,不是变量。
下面是嵌套赋值的例子。
|
|
如果解构模式是嵌套的对象,而且子对象所在的父属性不存在,那么将会报错。
|
|
上面代码中,等号左边对象的foo属性,对应一个子对象。该子对象的bar属性,解构时会报错。原因很简单,因为foo这时等于undefined,再取子属性就会报错。
注意,对象的解构赋值可以取到继承的属性。
|
|
上面代码中,对象obj1的原型对象是obj2。foo属性不是obj1自身的属性,而是继承自obj2的属性,解构赋值可以取到这个属性。
默认值
对象的解构也可以指定默认值。
|
|
默认值生效的条件是,对象的属性值严格等于undefined。
|
|
上面代码中,属性x等于null,因为null与undefined不严格相等,所以是个有效的赋值,导致默认值3不会生效。
注意点
(1)如果要将一个已经声明的变量用于解构赋值,必须非常小心。
|
|
上面代码的写法会报错,因为 JavaScript 引擎会将{x}理解成一个代码块,从而发生语法错误。只有不将大括号写在行首,避免 JavaScript 将其解释为代码块,才能解决这个问题。
|
|
上面代码将整个解构赋值语句,放在一个圆括号里面,就可以正确执行。关于圆括号与解构赋值的关系,参见下文。
(2)解构赋值允许等号左边的模式之中,不放置任何变量名。因此,可以写出非常古怪的赋值表达式。
|
|
上面的表达式虽然毫无意义,但是语法是合法的,可以执行。
(3)由于数组本质是特殊的对象,因此可以对数组进行对象属性的解构。
|
|
上面代码对数组进行对象解构。数组arr的0键对应的值是1,[arr.length - 1]就是2键,对应的值是3。方括号这种写法,属于“属性名表达式”(参见《对象的扩展》一章)。
字符串的解构赋值
字符串也可以解构赋值。这是因为此时,字符串被转换成了一个类似数组的对象。
|
|
类似数组的对象都有一个length属性,因此还可以对这个属性解构赋值。
|
|
数值和布尔值的解构赋值
解构赋值时,如果等号右边是数值和布尔值,则会先转为对象。
|
|
上面代码中,数值和布尔值的包装对象都有toString属性,因此变量s都能取到值。
解构赋值的规则是,只要等号右边的值不是对象或数组,就先将其转为对象。由于undefined和null无法转为对象,所以对它们进行解构赋值,都会报错。
|
|
函数参数的解构赋值
函数的参数也可以使用解构赋值。
|
|
上面代码中,函数add的参数表面上是一个数组,但在传入参数的那一刻,数组参数就被解构成变量x和y。对于函数内部的代码来说,它们能感受到的参数就是x和y。
下面是另一个例子。
|
|
函数参数的解构也可以使用默认值。
|
|
上面代码中,函数move的参数是一个对象,通过对这个对象进行解构,得到变量x和y的值。如果解构失败,x和y等于默认值。
注意,下面的写法会得到不一样的结果。
|
|
上面代码是为函数move的参数指定默认值,而不是为变量x和y指定默认值,所以会得到与前一种写法不同的结果。
undefined就会触发函数参数的默认值。
|
|
解构赋值圆括号问题
解构赋值虽然很方便,但是解析起来并不容易。对于编译器来说,一个式子到底是模式,还是表达式,没有办法从一开始就知道,必须解析到(或解析不到)等号才能知道。
由此带来的问题是,如果模式中出现圆括号怎么处理。ES6 的规则是,只要有可能导致解构的歧义,就不得使用圆括号。
但是,这条规则实际上不那么容易辨别,处理起来相当麻烦。因此,建议只要有可能,就不要在模式中放置圆括号。
不能使用圆括号的情况
以下三种解构赋值不得使用圆括号。
(1)变量声明语句
|
|
上面 6 个语句都会报错,因为它们都是变量声明语句,模式不能使用圆括号。
(2)函数参数
函数参数也属于变量声明,因此不能带有圆括号。
|
|
(3)赋值语句的模式
|
|
上面代码将整个模式放在圆括号之中,导致报错。
|
|
上面代码将一部分模式放在圆括号之中,导致报错。
可以使用圆括号的情况
可以使用圆括号的情况只有一种:赋值语句的非模式部分,可以使用圆括号。
|
|
上面三行语句都可以正确执行,因为首先它们都是赋值语句,而不是声明语句;其次它们的圆括号都不属于模式的一部分。第一行语句中,模式是取数组的第一个成员,跟圆括号无关;第二行语句中,模式是p,而不是d;第三行语句与第一行语句的性质一致。
解构赋值的用途
变量的解构赋值用途很多。
(1)交换变量的值
|
|
上面代码交换变量x和y的值,这样的写法不仅简洁,而且易读,语义非常清晰。
(2)从函数返回多个值
函数只能返回一个值,如果要返回多个值,只能将它们放在数组或对象里返回。有了解构赋值,取出这些值就非常方便。
|
|
(3)函数参数的定义
解构赋值可以方便地将一组参数与变量名对应起来。
|
|
(4)提取 JSON 数据
解构赋值对提取 JSON 对象中的数据,尤其有用。
|
|
上面代码可以快速提取 JSON 数据的值。
(5)函数参数的默认值
|
|
指定参数的默认值,就避免了在函数体内部再写var foo = config.foo || 'default foo';这样的语句。
(6)遍历 Map 结构
任何部署了 Iterator 接口的对象,都可以用for...of循环遍历。Map 结构原生支持 Iterator 接口,配合变量的解构赋值,获取键名和键值就非常方便。
|
|
如果只想获取键名,或者只想获取键值,可以写成下面这样。
|
|
(7)输入模块的指定方法
加载模块时,往往需要指定输入哪些方法。解构赋值使得输入语句非常清晰。
|
|
函数的扩展
函数参数的默认值
基本用法
ES6 之前,不能直接为函数的参数指定默认值,只能采用变通的方法。
|
|
上面代码检查函数log()的参数y有没有赋值,如果没有,则指定默认值为World。这种写法的缺点在于,如果参数y赋值了,但是对应的布尔值为false,则该赋值不起作用。就像上面代码的最后一行,参数y等于空字符,结果被改为默认值。
为了避免这个问题,通常需要先判断一下参数y是否被赋值,如果没有,再等于默认值。
|
|
ES6 允许为函数的参数设置默认值,即直接写在参数定义的后面。
|
|
可以看到,ES6 的写法比 ES5 简洁许多,而且非常自然。下面是另一个例子。
|
|
除了简洁,ES6 的写法还有两个好处:首先,阅读代码的人,可以立刻意识到哪些参数是可以省略的,不用查看函数体或文档;其次,有利于将来的代码优化,即使未来的版本在对外接口中,彻底拿掉这个参数,也不会导致以前的代码无法运行。
参数变量是默认声明的,所以不能用let或const再次声明。
|
|
上面代码中,参数变量x是默认声明的,在函数体中,不能用let或const再次声明,否则会报错。
使用参数默认值时,函数不能有同名参数。
|
|
另外,一个容易忽略的地方是,参数默认值不是传值的,而是每次都重新计算默认值表达式的值。也就是说,参数默认值是惰性求值的。
|
|
上面代码中,参数p的默认值是x + 1。这时,每次调用函数foo(),都会重新计算x + 1,而不是默认p等于 100。
与解构赋值默认值结合使用
参数默认值可以与解构赋值的默认值,结合起来使用。
|
|
上面代码只使用了对象的解构赋值默认值,没有使用函数参数的默认值。只有当函数foo()的参数是一个对象时,变量x和y才会通过解构赋值生成。如果函数foo()调用时没提供参数,变量x和y就不会生成,从而报错。通过提供函数参数的默认值,就可以避免这种情况。
|
|
上面代码指定,如果没有提供参数,函数foo的参数默认为一个空对象。
下面是另一个解构赋值默认值的例子。
|
|
上面代码中,如果函数fetch()的第二个参数是一个对象,就可以为它的三个属性设置默认值。这种写法不能省略第二个参数,如果结合函数参数的默认值,就可以省略第二个参数。这时,就出现了双重默认值。
|
|
上面代码中,函数fetch没有第二个参数时,函数参数的默认值就会生效,然后才是解构赋值的默认值生效,变量method才会取到默认值GET。
注意,函数参数的默认值生效以后,参数解构赋值依然会进行。
|
|
上面示例中,函数f()调用时没有参数,所以参数默认值{ a: 'hello' }生效,然后再对这个默认值进行解构赋值,从而触发参数变量b的默认值生效。
作为练习,大家可以思考一下,下面两种函数写法有什么差别?
|
|
参数默认值的位置
通常情况下,定义了默认值的参数,应该是函数的尾参数。因为这样比较容易看出来,到底省略了哪些参数。如果非尾部的参数设置默认值,实际上这个参数是没法省略的。
|
|
上面代码中,有默认值的参数都不是尾参数。这时,无法只省略该参数,而不省略它后面的参数,除非显式输入undefined。
如果传入undefined,将触发该参数等于默认值,null则没有这个效果。
|
|
上面代码中,x参数对应undefined,结果触发了默认值,y参数等于null,就没有触发默认值。
函数的 length 属性
指定了默认值以后,函数的length属性,将返回没有指定默认值的参数个数。也就是说,指定了默认值后,length属性将失真。
|
|
上面代码中,length属性的返回值,等于函数的参数个数减去指定了默认值的参数个数。比如,上面最后一个函数,定义了 3 个参数,其中有一个参数c指定了默认值,因此length属性等于3减去1,最后得到2。
这是因为length属性的含义是,该函数预期传入的参数个数。某个参数指定默认值以后,预期传入的参数个数就不包括这个参数了。同理,后文的 rest 参数也不会计入length属性。
|
|
如果设置了默认值的参数不是尾参数,那么length属性也不再计入后面的参数了。
|
|
作用域
一旦设置了参数的默认值,函数进行声明初始化时,参数会形成一个单独的作用域(context)。等到初始化结束,这个作用域就会消失。这种语法行为,在不设置参数默认值时,是不会出现的。
|
|
上面代码中,参数y的默认值等于变量x。调用函数f时,参数形成一个单独的作用域。在这个作用域里面,默认值变量x指向第一个参数x,而不是全局变量x,所以输出是2。
再看下面的例子。
|
|
上面代码中,函数f调用时,参数y = x形成一个单独的作用域。这个作用域里面,变量x本身没有定义,所以指向外层的全局变量x。函数调用时,函数体内部的局部变量x影响不到默认值变量x。
如果此时,全局变量x不存在,就会报错。
|
|
下面这样写,也会报错。
|
|
上面代码中,参数x = x形成一个单独作用域。实际执行的是let x = x,由于暂时性死区的原因,这行代码会报错。
如果参数的默认值是一个函数,该函数的作用域也遵守这个规则。请看下面的例子。
|
|
上面代码中,函数bar的参数func的默认值是一个匿名函数,返回值为变量foo。函数参数形成的单独作用域里面,并没有定义变量foo,所以foo指向外层的全局变量foo,因此输出outer。
如果写成下面这样,就会报错。
|
|
上面代码中,匿名函数里面的foo指向函数外层,但是函数外层并没有声明变量foo,所以就报错了。
下面是一个更复杂的例子。
|
|
上面代码中,函数foo的参数形成一个单独作用域。这个作用域里面,首先声明了变量x,然后声明了变量y,y的默认值是一个匿名函数。这个匿名函数内部的变量x,指向同一个作用域的第一个参数x。函数foo内部又声明了一个内部变量x,该变量与第一个参数x由于不是同一个作用域,所以不是同一个变量,因此执行y后,内部变量x和外部全局变量x的值都没变。
如果将var x = 3的var去除,函数foo的内部变量x就指向第一个参数x,与匿名函数内部的x是一致的,所以最后输出的就是2,而外层的全局变量x依然不受影响。
|
|
应用
利用参数默认值,可以指定某一个参数不得省略,如果省略就抛出一个错误。
|
|
上面代码的foo函数,如果调用的时候没有参数,就会调用默认值throwIfMissing函数,从而抛出一个错误。
从上面代码还可以看到,参数mustBeProvided的默认值等于throwIfMissing函数的运行结果(注意函数名throwIfMissing之后有一对圆括号),这表明参数的默认值不是在定义时执行,而是在运行时执行。如果参数已经赋值,默认值中的函数就不会运行。
另外,可以将参数默认值设为undefined,表明这个参数是可以省略的。
|
|
rest 参数
ES6 引入 rest 参数(形式为...变量名),用于获取函数的多余参数,这样就不需要使用arguments对象了。rest 参数搭配的变量是一个数组,该变量将多余的参数放入数组中。
|
|
上面代码的add函数是一个求和函数,利用 rest 参数,可以向该函数传入任意数目的参数。
下面是一个 rest 参数代替arguments变量的例子。
|
|
上面代码的两种写法,比较后可以发现,rest 参数的写法更自然也更简洁。
arguments对象不是数组,而是一个类似数组的对象。所以为了使用数组的方法,必须使用Array.from先将其转为数组。rest 参数就不存在这个问题,它就是一个真正的数组,数组特有的方法都可以使用。下面是一个利用 rest 参数改写数组push方法的例子。
|
|
注意,rest 参数之后不能再有其他参数(即只能是最后一个参数),否则会报错。
|
|
函数的length属性,不包括 rest 参数。
|
|
严格模式
从 ES5 开始,函数内部可以设定为严格模式。
|
|
ES2016 做了一点修改,规定只要函数参数使用了默认值、解构赋值、或者扩展运算符,那么函数内部就不能显式设定为严格模式,否则会报错。
|
|
这样规定的原因是,函数内部的严格模式,同时适用于函数体和函数参数。但是,函数执行的时候,先执行函数参数,然后再执行函数体。这样就有一个不合理的地方,只有从函数体之中,才能知道参数是否应该以严格模式执行,但是参数却应该先于函数体执行。
|
|
上面代码中,参数value的默认值是八进制数070,但是严格模式下不能用前缀0表示八进制,所以应该报错。但是实际上,JavaScript 引擎会先成功执行value = 070,然后进入函数体内部,发现需要用严格模式执行,这时才会报错。
虽然可以先解析函数体代码,再执行参数代码,但是这样无疑就增加了复杂性。因此,标准索性禁止了这种用法,只要参数使用了默认值、解构赋值、或者扩展运算符,就不能显式指定严格模式。
两种方法可以规避这种限制。第一种是设定全局性的严格模式,这是合法的。
|
|
第二种是把函数包在一个无参数的立即执行函数里面。
|
|
name 属性
函数的name属性,返回该函数的函数名。
|
|
这个属性早就被浏览器广泛支持,但是直到 ES6,才将其写入了标准。
需要注意的是,ES6 对这个属性的行为做出了一些修改。如果将一个匿名函数赋值给一个变量,ES5 的name属性,会返回空字符串,而 ES6 的name属性会返回实际的函数名。
|
|
上面代码中,变量f等于一个匿名函数,ES5 和 ES6 的name属性返回的值不一样。
如果将一个具名函数赋值给一个变量,则 ES5 和 ES6 的name属性都返回这个具名函数原本的名字。
|
|
Function构造函数返回的函数实例,name属性的值为anonymous。
|
|
bind返回的函数,name属性值会加上bound前缀。
|
|
箭头函数
基本用法
ES6 允许使用“箭头”(=>)定义函数。
|
|
如果箭头函数不需要参数或需要多个参数,就使用一个圆括号代表参数部分。
|
|
如果箭头函数的代码块部分多于一条语句,就要使用大括号将它们括起来,并且使用return语句返回。
|
|
由于大括号被解释为代码块,所以如果箭头函数直接返回一个对象,必须在对象外面加上括号,否则会报错。
|
|
下面是一种特殊情况,虽然可以运行,但会得到错误的结果。
|
|
上面代码中,原始意图是返回一个对象{ a: 1 },但是由于引擎认为大括号是代码块,所以执行了一行语句a: 1。这时,a可以被解释为语句的标签,因此实际执行的语句是1;,然后函数就结束了,没有返回值。
如果箭头函数只有一行语句,且不需要返回值,可以采用下面的写法,就不用写大括号了。
|
|
箭头函数可以与变量解构结合使用。
|
|
箭头函数使得表达更加简洁。
|
|
上面代码只用了两行,就定义了两个简单的工具函数。如果不用箭头函数,可能就要占用多行,而且还不如现在这样写醒目。
箭头函数的一个用处是简化回调函数。
|
|
另一个例子是
|
|
下面是 rest 参数与箭头函数结合的例子。
|
|
使用注意点
箭头函数有几个使用注意点。
(1)箭头函数没有自己的this对象(详见下文)。
(2)不可以当作构造函数,也就是说,不可以对箭头函数使用new命令,否则会抛出一个错误。
(3)不可以使用arguments对象,该对象在函数体内不存在。如果要用,可以用 rest 参数代替。
(4)不可以使用yield命令,因此箭头函数不能用作 Generator 函数。
上面四点中,最重要的是第一点。对于普通函数来说,内部的this指向函数运行时所在的对象,但是这一点对箭头函数不成立。它没有自己的this对象,内部的this就是定义时上层作用域中的this。也就是说,箭头函数内部的this指向是固定的,相比之下,普通函数的this指向是可变的。
|
|
上面代码中,setTimeout()的参数是一个箭头函数,这个箭头函数的定义生效是在foo函数生成时,而它的真正执行要等到 100 毫秒后。如果是普通函数,执行时this应该指向全局对象window,这时应该输出21。但是,箭头函数导致this总是指向函数定义生效时所在的对象(本例是{id: 42}),所以打印出来的是42。
下面例子是回调函数分别为箭头函数和普通函数,对比它们内部的this指向。
|
|
上面代码中,Timer函数内部设置了两个定时器,分别使用了箭头函数和普通函数。前者的this绑定定义时所在的作用域(即Timer函数),后者的this指向运行时所在的作用域(即全局对象)。所以,3100 毫秒之后,timer.s1被更新了 3 次,而timer.s2一次都没更新。
箭头函数实际上可以让this指向固定化,绑定this使得它不再可变,这种特性很有利于封装回调函数。下面是一个例子,DOM 事件的回调函数封装在一个对象里面。
|
|
上面代码的init()方法中,使用了箭头函数,这导致这个箭头函数里面的this,总是指向handler对象。如果回调函数是普通函数,那么运行this.doSomething()这一行会报错,因为此时this指向document对象。
总之,箭头函数根本没有自己的this,导致内部的this就是外层代码块的this。正是因为它没有this,所以也就不能用作构造函数。
下面是 Babel 转箭头函数产生的 ES5 代码,就能清楚地说明this的指向。
|
|
上面代码中,转换后的 ES5 版本清楚地说明了,箭头函数里面根本没有自己的this,而是引用外层的this。
请问下面的代码之中,this的指向有几个?
|
|
答案是this的指向只有一个,就是函数foo的this,这是因为所有的内层函数都是箭头函数,都没有自己的this,它们的this其实都是最外层foo函数的this。所以不管怎么嵌套,t1、t2、t3都输出同样的结果。如果这个例子的所有内层函数都写成普通函数,那么每个函数的this都指向运行时所在的不同对象。
除了this,以下三个变量在箭头函数之中也是不存在的,指向外层函数的对应变量:arguments、super、new.target。
|
|
上面代码中,箭头函数内部的变量arguments,其实是函数foo的arguments变量。
另外,由于箭头函数没有自己的this,所以当然也就不能用call()、apply()、bind()这些方法去改变this的指向。
|
|
上面代码中,箭头函数没有自己的this,所以bind方法无效,内部的this指向外部的this。
长期以来,JavaScript 语言的this对象一直是一个令人头痛的问题,在对象方法中使用this,必须非常小心。箭头函数”绑定”this,很大程度上解决了这个困扰。
不适用场合
由于箭头函数使得this从“动态”变成“静态”,下面两个场合不应该使用箭头函数。
第一个场合是定义对象的方法,且该方法内部包括this。
|
|
上面代码中,cat.jumps()方法是一个箭头函数,这是错误的。调用cat.jumps()时,如果是普通函数,该方法内部的this指向cat;如果写成上面那样的箭头函数,使得this指向全局对象,因此不会得到预期结果。这是因为对象不构成单独的作用域,导致jumps箭头函数定义时的作用域就是全局作用域。
再看一个例子。
|
|
上面例子中,obj.m()使用箭头函数定义。JavaScript 引擎的处理方法是,先在全局空间生成这个箭头函数,然后赋值给obj.m,这导致箭头函数内部的this指向全局对象,所以obj.m()输出的是全局空间的21,而不是对象内部的42。上面的代码实际上等同于下面的代码。
|
|
由于上面这个原因,对象的属性建议使用传统的写法定义,不要用箭头函数定义。
第二个场合是需要动态this的时候,也不应使用箭头函数。
|
|
上面代码运行时,点击按钮会报错,因为button的监听函数是一个箭头函数,导致里面的this就是全局对象。如果改成普通函数,this就会动态指向被点击的按钮对象。
另外,如果函数体很复杂,有许多行,或者函数内部有大量的读写操作,不单纯是为了计算值,这时也不应该使用箭头函数,而是要使用普通函数,这样可以提高代码可读性。
嵌套的箭头函数
箭头函数内部,还可以再使用箭头函数。下面是一个 ES5 语法的多重嵌套函数。
|
|
上面这个函数,可以使用箭头函数改写。
|
|
下面是一个部署管道机制(pipeline)的例子,即前一个函数的输出是后一个函数的输入。
|
|
如果觉得上面的写法可读性比较差,也可以采用下面的写法。
|
|
箭头函数还有一个功能,就是可以很方便地改写 λ 演算。
|
|
上面两种写法,几乎是一一对应的。由于 λ 演算对于计算机科学非常重要,这使得我们可以用 ES6 作为替代工具,探索计算机科学。
尾调用优化
什么是尾调用?
尾调用(Tail Call)是函数式编程的一个重要概念,本身非常简单,一句话就能说清楚,就是指某个函数的最后一步是调用另一个函数。
|
|
上面代码中,函数f的最后一步是调用函数g,这就叫尾调用。
以下三种情况,都不属于尾调用。
|
|
上面代码中,情况一是调用函数g之后,还有赋值操作,所以不属于尾调用,即使语义完全一样。情况二也属于调用后还有操作,即使写在一行内。情况三等同于下面的代码。
|
|
尾调用不一定出现在函数尾部,只要是最后一步操作即可。
|
|
上面代码中,函数m和n都属于尾调用,因为它们都是函数f的最后一步操作。
尾调用优化
尾调用之所以与其他调用不同,就在于它的特殊的调用位置。
我们知道,函数调用会在内存形成一个“调用记录”,又称“调用帧”(call frame),保存调用位置和内部变量等信息。如果在函数A的内部调用函数B,那么在A的调用帧上方,还会形成一个B的调用帧。等到B运行结束,将结果返回到A,B的调用帧才会消失。如果函数B内部还调用函数C,那就还有一个C的调用帧,以此类推。所有的调用帧,就形成一个“调用栈”(call stack)。
尾调用由于是函数的最后一步操作,所以不需要保留外层函数的调用帧,因为调用位置、内部变量等信息都不会再用到了,只要直接用内层函数的调用帧,取代外层函数的调用帧就可以了。
|
|
上面代码中,如果函数g不是尾调用,函数f就需要保存内部变量m和n的值、g的调用位置等信息。但由于调用g之后,函数f就结束了,所以执行到最后一步,完全可以删除f(x)的调用帧,只保留g(3)的调用帧。
这就叫做“尾调用优化”(Tail call optimization),即只保留内层函数的调用帧。如果所有函数都是尾调用,那么完全可以做到每次执行时,调用帧只有一项,这将大大节省内存。这就是“尾调用优化”的意义。
注意,只有不再用到外层函数的内部变量,内层函数的调用帧才会取代外层函数的调用帧,否则就无法进行“尾调用优化”。
|
|
上面的函数不会进行尾调用优化,因为内层函数inner用到了外层函数addOne的内部变量one。
注意,目前只有 Safari 浏览器支持尾调用优化,Chrome 和 Firefox 都不支持。
尾递归
函数调用自身,称为递归。如果尾调用自身,就称为尾递归。
递归非常耗费内存,因为需要同时保存成千上百个调用帧,很容易发生“栈溢出”错误(stack overflow)。但对于尾递归来说,由于只存在一个调用帧,所以永远不会发生“栈溢出”错误。
|
|
上面代码是一个阶乘函数,计算n的阶乘,最多需要保存n个调用记录,复杂度 O(n) 。
如果改写成尾递归,只保留一个调用记录,复杂度 O(1) 。
|
|
还有一个比较著名的例子,就是计算 Fibonacci 数列,也能充分说明尾递归优化的重要性。
非尾递归的 Fibonacci 数列实现如下。
|
|
尾递归优化过的 Fibonacci 数列实现如下。
|
|
由此可见,“尾调用优化”对递归操作意义重大,所以一些函数式编程语言将其写入了语言规格。ES6 亦是如此,第一次明确规定,所有 ECMAScript 的实现,都必须部署“尾调用优化”。这就是说,ES6 中只要使用尾递归,就不会发生栈溢出(或者层层递归造成的超时),相对节省内存。
递归函数的改写
尾递归的实现,往往需要改写递归函数,确保最后一步只调用自身。做到这一点的方法,就是把所有用到的内部变量改写成函数的参数。比如上面的例子,阶乘函数 factorial 需要用到一个中间变量total,那就把这个中间变量改写成函数的参数。这样做的缺点就是不太直观,第一眼很难看出来,为什么计算5的阶乘,需要传入两个参数5和1?
两个方法可以解决这个问题。方法一是在尾递归函数之外,再提供一个正常形式的函数。
|
|
上面代码通过一个正常形式的阶乘函数factorial,调用尾递归函数tailFactorial,看起来就正常多了。
函数式编程有一个概念,叫做柯里化(currying),意思是将多参数的函数转换成单参数的形式。这里也可以使用柯里化。
|
|
上面代码通过柯里化,将尾递归函数tailFactorial变为只接受一个参数的factorial。
第二种方法就简单多了,就是采用 ES6 的函数默认值。
|
|
上面代码中,参数total有默认值1,所以调用时不用提供这个值。
总结一下,递归本质上是一种循环操作。纯粹的函数式编程语言没有循环操作命令,所有的循环都用递归实现,这就是为什么尾递归对这些语言极其重要。对于其他支持“尾调用优化”的语言(比如 Lua,ES6),只需要知道循环可以用递归代替,而一旦使用递归,就最好使用尾递归。
严格模式
ES6 的尾调用优化只在严格模式下开启,正常模式是无效的。
这是因为在正常模式下,函数内部有两个变量,可以跟踪函数的调用栈。
func.arguments:返回调用时函数的参数。func.caller:返回调用当前函数的那个函数。
尾调用优化发生时,函数的调用栈会改写,因此上面两个变量就会失真。严格模式禁用这两个变量,所以尾调用模式仅在严格模式下生效。
|
|
尾递归优化的实现
尾递归优化只在严格模式下生效,那么正常模式下,或者那些不支持该功能的环境中,有没有办法也使用尾递归优化呢?回答是可以的,就是自己实现尾递归优化。
它的原理非常简单。尾递归之所以需要优化,原因是调用栈太多,造成溢出,那么只要减少调用栈,就不会溢出。怎么做可以减少调用栈呢?就是采用“循环”换掉“递归”。
下面是一个正常的递归函数。
|
|
上面代码中,sum是一个递归函数,参数x是需要累加的值,参数y控制递归次数。一旦指定sum递归 100000 次,就会报错,提示超出调用栈的最大次数。
蹦床函数(trampoline)可以将递归执行转为循环执行。
|
|
上面就是蹦床函数的一个实现,它接受一个函数f作为参数。只要f执行后返回一个函数,就继续执行。注意,这里是返回一个函数,然后执行该函数,而不是函数里面调用函数,这样就避免了递归执行,从而就消除了调用栈过大的问题。
然后,要做的就是将原来的递归函数,改写为每一步返回另一个函数。
|
|
上面代码中,sum函数的每次执行,都会返回自身的另一个版本。
现在,使用蹦床函数执行sum,就不会发生调用栈溢出。
|
|
蹦床函数并不是真正的尾递归优化,下面的实现才是。
|
|
上面代码中,tco函数是尾递归优化的实现,它的奥妙就在于状态变量active。默认情况下,这个变量是不激活的。一旦进入尾递归优化的过程,这个变量就激活了。然后,每一轮递归sum返回的都是undefined,所以就避免了递归执行;而accumulated数组存放每一轮sum执行的参数,总是有值的,这就保证了accumulator函数内部的while循环总是会执行。这样就很巧妙地将“递归”改成了“循环”,而后一轮的参数会取代前一轮的参数,保证了调用栈只有一层。
函数参数的尾逗号
ES2017 允许函数的最后一个参数有尾逗号(trailing comma)。
此前,函数定义和调用时,都不允许最后一个参数后面出现逗号。
|
|
上面代码中,如果在param2或bar后面加一个逗号,就会报错。
如果像上面这样,将参数写成多行(即每个参数占据一行),以后修改代码的时候,想为函数clownsEverywhere添加第三个参数,或者调整参数的次序,就势必要在原来最后一个参数后面添加一个逗号。这对于版本管理系统来说,就会显示添加逗号的那一行也发生了变动。这看上去有点冗余,因此新的语法允许定义和调用时,尾部直接有一个逗号。
|
|
这样的规定也使得,函数参数与数组和对象的尾逗号规则,保持一致了。
Function.prototype.toString()
ES2019 对函数实例的toString()方法做出了修改。
toString()方法返回函数代码本身,以前会省略注释和空格。
|
|
上面代码中,函数foo的原始代码包含注释,函数名foo和圆括号之间有空格,但是toString()方法都把它们省略了。
修改后的toString()方法,明确要求返回一模一样的原始代码。
|
|
catch 命令的参数省略
JavaScript 语言的try...catch结构,以前明确要求catch命令后面必须跟参数,接受try代码块抛出的错误对象。
|
|
上面代码中,catch命令后面带有参数err。
很多时候,catch代码块可能用不到这个参数。但是,为了保证语法正确,还是必须写。ES2019 做出了改变,允许catch语句省略参数。
|
|
数组的扩展
扩展运算符
含义
扩展运算符(spread)是三个点(...)。它好比 rest 参数的逆运算,将一个数组转为用逗号分隔的参数序列。
|
|
该运算符主要用于函数调用。
|
|
上面代码中,array.push(...items)和add(...numbers)这两行,都是函数的调用,它们都使用了扩展运算符。该运算符将一个数组,变为参数序列。
扩展运算符与正常的函数参数可以结合使用,非常灵活。
|
|
扩展运算符后面还可以放置表达式。
|
|
如果扩展运算符后面是一个空数组,则不产生任何效果。
|
|
注意,只有函数调用时,扩展运算符才可以放在圆括号中,否则会报错。
|
|
上面三种情况,扩展运算符都放在圆括号里面,但是前两种情况会报错,因为扩展运算符所在的括号不是函数调用。
替代函数的 apply() 方法
由于扩展运算符可以展开数组,所以不再需要apply()方法将数组转为函数的参数了。
|
|
下面是扩展运算符取代apply()方法的一个实际的例子,应用Math.max()方法,简化求出一个数组最大元素的写法。
|
|
上面代码中,由于 JavaScript 不提供求数组最大元素的函数,所以只能套用Math.max()函数,将数组转为一个参数序列,然后求最大值。有了扩展运算符以后,就可以直接用Math.max()了。
另一个例子是通过push()函数,将一个数组添加到另一个数组的尾部。
|
|
上面代码的 ES5 写法中,push()方法的参数不能是数组,所以只好通过apply()方法变通使用push()方法。有了扩展运算符,就可以直接将数组传入push()方法。
下面是另外一个例子。
|
|
扩展运算符的应用
(1)复制数组
数组是复合的数据类型,直接复制的话,只是复制了指向底层数据结构的指针,而不是克隆一个全新的数组。
|
|
上面代码中,a2并不是a1的克隆,而是指向同一份数据的另一个指针。修改a2,会直接导致a1的变化。
ES5 只能用变通方法来复制数组。
|
|
上面代码中,a1会返回原数组的克隆,再修改a2就不会对a1产生影响。
扩展运算符提供了复制数组的简便写法。
|
|
上面的两种写法,a2都是a1的克隆。
(2)合并数组
扩展运算符提供了数组合并的新写法。
|
|
不过,这两种方法都是浅拷贝,使用的时候需要注意。
|
|
上面代码中,a3和a4是用两种不同方法合并而成的新数组,但是它们的成员都是对原数组成员的引用,这就是浅拷贝。如果修改了引用指向的值,会同步反映到新数组。
(3)与解构赋值结合
扩展运算符可以与解构赋值结合起来,用于生成数组。
|
|
下面是另外一些例子。
|
|
如果将扩展运算符用于数组赋值,只能放在参数的最后一位,否则会报错。
|
|
(4)字符串
扩展运算符还可以将字符串转为真正的数组。
|
|
上面的写法,有一个重要的好处,那就是能够正确识别四个字节的 Unicode 字符。
|
|
上面代码的第一种写法,JavaScript 会将四个字节的 Unicode 字符,识别为 2 个字符,采用扩展运算符就没有这个问题。因此,正确返回字符串长度的函数,可以像下面这样写。
|
|
凡是涉及到操作四个字节的 Unicode 字符的函数,都有这个问题。因此,最好都用扩展运算符改写。
|
|
上面代码中,如果不用扩展运算符,字符串的reverse()操作就不正确。
(5)实现了 Iterator 接口的对象
任何定义了遍历器(Iterator)接口的对象(参阅 Iterator 一章),都可以用扩展运算符转为真正的数组。
|
|
上面代码中,querySelectorAll()方法返回的是一个NodeList对象。它不是数组,而是一个类似数组的对象。这时,扩展运算符可以将其转为真正的数组,原因就在于NodeList对象实现了 Iterator。
|
|
上面代码中,先定义了Number对象的遍历器接口,扩展运算符将5自动转成Number实例以后,就会调用这个接口,就会返回自定义的结果。
对于那些没有部署 Iterator 接口的类似数组的对象,扩展运算符就无法将其转为真正的数组。
|
|
上面代码中,arrayLike是一个类似数组的对象,但是没有部署 Iterator 接口,扩展运算符就会报错。这时,可以改为使用Array.from方法将arrayLike转为真正的数组。
(6)Map 和 Set 结构,Generator 函数
扩展运算符内部调用的是数据结构的 Iterator 接口,因此只要具有 Iterator 接口的对象,都可以使用扩展运算符,比如 Map 结构。
|
|
Generator 函数运行后,返回一个遍历器对象,因此也可以使用扩展运算符。
|
|
上面代码中,变量go是一个 Generator 函数,执行后返回的是一个遍历器对象,对这个遍历器对象执行扩展运算符,就会将内部遍历得到的值,转为一个数组。
如果对没有 Iterator 接口的对象,使用扩展运算符,将会报错。
|
|
Array.from()
Array.from()方法用于将两类对象转为真正的数组:类似数组的对象(array-like object)和可遍历(iterable)的对象(包括 ES6 新增的数据结构 Set 和 Map)。
下面是一个类似数组的对象,Array.from()将它转为真正的数组。
|
|
实际应用中,常见的类似数组的对象是 DOM 操作返回的 NodeList 集合,以及函数内部的arguments对象。Array.from()都可以将它们转为真正的数组。
|
|
上面代码中,querySelectorAll()方法返回的是一个类似数组的对象,可以将这个对象转为真正的数组,再使用filter()方法。
只要是部署了 Iterator 接口的数据结构,Array.from()都能将其转为数组。
|
|
上面代码中,字符串和 Set 结构都具有 Iterator 接口,因此可以被Array.from()转为真正的数组。
如果参数是一个真正的数组,Array.from()会返回一个一模一样的新数组。
|
|
值得提醒的是,扩展运算符(...)也可以将某些数据结构转为数组。
|
|
扩展运算符背后调用的是遍历器接口(Symbol.iterator),如果一个对象没有部署这个接口,就无法转换。Array.from()方法还支持类似数组的对象。所谓类似数组的对象,本质特征只有一点,即必须有length属性。因此,任何有length属性的对象,都可以通过Array.from()方法转为数组,而此时扩展运算符就无法转换。
|
|
上面代码中,Array.from()返回了一个具有三个成员的数组,每个位置的值都是undefined。扩展运算符转换不了这个对象。
对于还没有部署该方法的浏览器,可以用Array.prototype.slice()方法替代。
|
|
Array.from()还可以接受一个函数作为第二个参数,作用类似于数组的map()方法,用来对每个元素进行处理,将处理后的值放入返回的数组。
|
|
下面的例子是取出一组 DOM 节点的文本内容。
|
|
下面的例子将数组中布尔值为false的成员转为0。
|
|
另一个例子是返回各种数据的类型。
|
|
如果map()函数里面用到了this关键字,还可以传入Array.from()的第三个参数,用来绑定this。
Array.from()可以将各种值转为真正的数组,并且还提供map功能。这实际上意味着,只要有一个原始的数据结构,你就可以先对它的值进行处理,然后转成规范的数组结构,进而就可以使用数量众多的数组方法。
|
|
上面代码中,Array.from()的第一个参数指定了第二个参数运行的次数。这种特性可以让该方法的用法变得非常灵活。
Array.from()的另一个应用是,将字符串转为数组,然后返回字符串的长度。因为它能正确处理各种 Unicode 字符,可以避免 JavaScript 将大于\uFFFF的 Unicode 字符,算作两个字符的 bug。
|
|
Array.of()
Array.of()方法用于将一组值,转换为数组。
|
|
这个方法的主要目的,是弥补数组构造函数Array()的不足。因为参数个数的不同,会导致Array()的行为有差异。
|
|
上面代码中,Array()方法没有参数、一个参数、三个参数时,返回的结果都不一样。只有当参数个数不少于 2 个时,Array()才会返回由参数组成的新数组。参数只有一个正整数时,实际上是指定数组的长度。
Array.of()基本上可以用来替代Array()或new Array(),并且不存在由于参数不同而导致的重载。它的行为非常统一。
|
|
Array.of()总是返回参数值组成的数组。如果没有参数,就返回一个空数组。
Array.of()方法可以用下面的代码模拟实现。
|
|
实例方法:copyWithin()
数组实例的copyWithin()方法,在当前数组内部,将指定位置的成员复制到其他位置(会覆盖原有成员),然后返回当前数组。也就是说,使用这个方法,会修改当前数组。
|
|
它接受三个参数。
- target(必需):从该位置开始替换数据。如果为负值,表示倒数。
- start(可选):从该位置开始读取数据,默认为 0。如果为负值,表示从末尾开始计算。
- end(可选):到该位置前停止读取数据,默认等于数组长度。如果为负值,表示从末尾开始计算。
这三个参数都应该是数值,如果不是,会自动转为数值。
|
|
上面代码表示将从 3 号位直到数组结束的成员(4 和 5),复制到从 0 号位开始的位置,结果覆盖了原来的 1 和 2。
下面是更多例子。
|
|
实例方法:find(),findIndex(),findLast(),findLastIndex()
数组实例的find()方法,用于找出第一个符合条件的数组成员。它的参数是一个回调函数,所有数组成员依次执行该回调函数,直到找出第一个返回值为true的成员,然后返回该成员。如果没有符合条件的成员,则返回undefined。
|
|
上面代码找出数组中第一个小于 0 的成员。
|
|
上面代码中,find()方法的回调函数可以接受三个参数,依次为当前的值、当前的位置和原数组。
数组实例的findIndex()方法的用法与find()方法非常类似,返回第一个符合条件的数组成员的位置,如果所有成员都不符合条件,则返回-1。
|
|
这两个方法都可以接受第二个参数,用来绑定回调函数的this对象。
|
|
上面的代码中,find()函数接收了第二个参数person对象,回调函数中的this对象指向person对象。
另外,这两个方法都可以发现NaN,弥补了数组的indexOf()方法的不足。
|
|
上面代码中,indexOf()方法无法识别数组的NaN成员,但是findIndex()方法可以借助Object.is()方法做到。
find()和findIndex()都是从数组的 0 号位,依次向后检查。ES2022 新增了两个方法findLast()和findLastIndex(),从数组的最后一个成员开始,依次向前检查,其他都保持不变。
|
|
上面示例中,findLast()和findLastIndex()从数组结尾开始,寻找第一个value属性为奇数的成员。结果,该成员是{ value: 3 },位置是 2 号位。
实例方法:fill()
fill方法使用给定值,填充一个数组。
|
|
上面代码表明,fill方法用于空数组的初始化非常方便。数组中已有的元素,会被全部抹去。
fill方法还可以接受第二个和第三个参数,用于指定填充的起始位置和结束位置。
|
|
上面代码表示,fill方法从 1 号位开始,向原数组填充 7,到 2 号位之前结束。
注意,如果填充的类型为对象,那么被赋值的是同一个内存地址的对象,而不是深拷贝对象。
|
|
实例方法:entries(),keys() 和 values()
ES6 提供三个新的方法——entries(),keys()和values()——用于遍历数组。它们都返回一个遍历器对象(详见《Iterator》一章),可以用for...of循环进行遍历,唯一的区别是keys()是对键名的遍历、values()是对键值的遍历,entries()是对键值对的遍历。
|
|
如果不使用for...of循环,可以手动调用遍历器对象的next方法,进行遍历。
|
|
实例方法:includes()
Array.prototype.includes方法返回一个布尔值,表示某个数组是否包含给定的值,与字符串的includes方法类似。ES2016 引入了该方法。
|
|
该方法的第二个参数表示搜索的起始位置,默认为0。如果第二个参数为负数,则表示倒数的位置,如果这时它大于数组长度(比如第二个参数为-4,但数组长度为3),则会重置为从0开始。
|
|
没有该方法之前,我们通常使用数组的indexOf方法,检查是否包含某个值。
|
|
indexOf方法有两个缺点,一是不够语义化,它的含义是找到参数值的第一个出现位置,所以要去比较是否不等于-1,表达起来不够直观。二是,它内部使用严格相等运算符(===)进行判断,这会导致对NaN的误判。
|
|
includes使用的是不一样的判断算法,就没有这个问题。
|
|
下面代码用来检查当前环境是否支持该方法,如果不支持,部署一个简易的替代版本。
|
|
另外,Map 和 Set 数据结构有一个has方法,需要注意与includes区分。
- Map 结构的
has方法,是用来查找键名的,比如Map.prototype.has(key)、WeakMap.prototype.has(key)、Reflect.has(target, propertyKey)。 - Set 结构的
has方法,是用来查找值的,比如Set.prototype.has(value)、WeakSet.prototype.has(value)。
实例方法:flat(),flatMap()
数组的成员有时还是数组,Array.prototype.flat()用于将嵌套的数组“拉平”,变成一维的数组。该方法返回一个新数组,对原数据没有影响。
|
|
上面代码中,原数组的成员里面有一个数组,flat()方法将子数组的成员取出来,添加在原来的位置。
flat()默认只会“拉平”一层,如果想要“拉平”多层的嵌套数组,可以将flat()方法的参数写成一个整数,表示想要拉平的层数,默认为 1。
|
|
上面代码中,flat()的参数为 2,表示要“拉平”两层的嵌套数组。
如果不管有多少层嵌套,都要转成一维数组,可以用Infinity关键字作为参数。
|
|
如果原数组有空位,flat()方法会跳过空位。
|
|
flatMap()方法对原数组的每个成员执行一个函数(相当于执行Array.prototype.map()),然后对返回值组成的数组执行flat()方法。该方法返回一个新数组,不改变原数组。
|
|
flatMap()只能展开一层数组。
|
|
上面代码中,遍历函数返回的是一个双层的数组,但是默认只能展开一层,因此flatMap()返回的还是一个嵌套数组。
flatMap()方法的参数是一个遍历函数,该函数可以接受三个参数,分别是当前数组成员、当前数组成员的位置(从零开始)、原数组。
|
|
flatMap()方法还可以有第二个参数,用来绑定遍历函数里面的this。
实例方法:at()
长久以来,JavaScript 不支持数组的负索引,如果要引用数组的最后一个成员,不能写成arr[-1],只能使用arr[arr.length - 1]。
这是因为方括号运算符[]在 JavaScript 语言里面,不仅用于数组,还用于对象。对于对象来说,方括号里面就是键名,比如obj[1]引用的是键名为字符串1的键,同理obj[-1]引用的是键名为字符串-1的键。由于 JavaScript 的数组是特殊的对象,所以方括号里面的负数无法再有其他语义了,也就是说,不可能添加新语法来支持负索引。
为了解决这个问题,ES2022 为数组实例增加了at()方法,接受一个整数作为参数,返回对应位置的成员,并支持负索引。这个方法不仅可用于数组,也可用于字符串和类型数组(TypedArray)。
|
|
如果参数位置超出了数组范围,at()返回undefined。
|
|
实例方法:toReversed(),toSorted(),toSpliced(),with()
很多数组的传统方法会改变原数组,比如push()、pop()、shift()、unshift()等等。数组只要调用了这些方法,它的值就变了。现在有一个提案,允许对数组进行操作时,不改变原数组,而返回一个原数组的拷贝。
这样的方法一共有四个。
Array.prototype.toReversed() -> ArrayArray.prototype.toSorted(compareFn) -> ArrayArray.prototype.toSpliced(start, deleteCount, ...items) -> ArrayArray.prototype.with(index, value) -> Array
它们分别对应数组的原有方法。
toReversed()对应reverse(),用来颠倒数组成员的位置。toSorted()对应sort(),用来对数组成员排序。toSpliced()对应splice(),用来在指定位置,删除指定数量的成员,并插入新成员。with(index, value)对应splice(index, 1, value),用来将指定位置的成员替换为新的值。
上面是这四个新方法对应的原有方法,含义和用法完全一样,唯一不同的是不会改变原数组,而是返回原数组操作后的拷贝。
下面是示例。
|
|
实例方法:group(),groupToMap()
数组成员分组是一个常见需求,比如 SQL 有GROUP BY子句和函数式编程有 MapReduce 方法。现在有一个提案,为 JavaScript 新增了数组实例方法group()和groupToMap(),它们可以根据分组函数的运行结果,将数组成员分组。
group()的参数是一个分组函数,原数组的每个成员都会依次执行这个函数,确定自己是哪一个组。
|
|
group()的分组函数可以接受三个参数,依次是数组的当前成员、该成员的位置序号、原数组(上例是num、index和array)。分组函数的返回值应该是字符串(或者可以自动转为字符串),以作为分组后的组名。
group()的返回值是一个对象,该对象的键名就是每一组的组名,即分组函数返回的每一个字符串(上例是even和odd);该对象的键值是一个数组,包括所有产生当前键名的原数组成员。
下面是另一个例子。
|
|
上面示例中,Math.floor作为分组函数,对原数组进行分组。它的返回值原本是数值,这时会自动转为字符串,作为分组的组名。原数组的成员根据分组函数的运行结果,进入对应的组。
group()还可以接受一个对象,作为第二个参数。该对象会绑定分组函数(第一个参数)里面的this,不过如果分组函数是一个箭头函数,该对象无效,因为箭头函数内部的this是固化的。
groupToMap()的作用和用法与group()完全一致,唯一的区别是返回值是一个 Map 结构,而不是对象。Map 结构的键名可以是各种值,所以不管分组函数返回什么值,都会直接作为组名(Map 结构的键名),不会强制转为字符串。这对于分组函数返回值是对象的情况,尤其有用。
|
|
上面示例返回的是一个 Map 结构,它的键名就是分组函数返回的两个对象odd和even。
总之,按照字符串分组就使用group(),按照对象分组就使用groupToMap()。
数组的空位
数组的空位指的是,数组的某一个位置没有任何值,比如Array()构造函数返回的数组都是空位。
|
|
上面代码中,Array(3)返回一个具有 3 个空位的数组。
注意,空位不是undefined,某一个位置的值等于undefined,依然是有值的。空位是没有任何值,in运算符可以说明这一点。
|
|
上面代码说明,第一个数组的 0 号位置是有值的,第二个数组的 0 号位置没有值。
ES5 对空位的处理,已经很不一致了,大多数情况下会忽略空位。
forEach(),filter(),reduce(),every()和some()都会跳过空位。map()会跳过空位,但会保留这个值join()和toString()会将空位视为undefined,而undefined和null会被处理成空字符串。
|
|
ES6 则是明确将空位转为undefined。
Array.from()方法会将数组的空位,转为undefined,也就是说,这个方法不会忽略空位。
|
|
扩展运算符(...)也会将空位转为undefined。
|
|
copyWithin()会连空位一起拷贝。
|
|
fill()会将空位视为正常的数组位置。
|
|
for...of循环也会遍历空位。
|
|
上面代码中,数组arr有两个空位,for...of并没有忽略它们。如果改成map()方法遍历,空位是会跳过的。
entries()、keys()、values()、find()和findIndex()会将空位处理成undefined。
|
|
由于空位的处理规则非常不统一,所以建议避免出现空位。
Array.prototype.sort() 的排序稳定性
排序稳定性(stable sorting)是排序算法的重要属性,指的是排序关键字相同的项目,排序前后的顺序不变。
|
|
上面代码对数组arr按照首字母进行排序。排序结果中,straw在spork的前面,跟原始顺序一致,所以排序算法stableSorting是稳定排序。
|
|
上面代码中,排序结果是spork在straw前面,跟原始顺序相反,所以排序算法unstableSorting是不稳定的。
常见的排序算法之中,插入排序、合并排序、冒泡排序等都是稳定的,堆排序、快速排序等是不稳定的。不稳定排序的主要缺点是,多重排序时可能会产生问题。假设有一个姓和名的列表,要求按照“姓氏为主要关键字,名字为次要关键字”进行排序。开发者可能会先按名字排序,再按姓氏进行排序。如果排序算法是稳定的,这样就可以达到“先姓氏,后名字”的排序效果。如果是不稳定的,就不行。
早先的 ECMAScript 没有规定,Array.prototype.sort()的默认排序算法是否稳定,留给浏览器自己决定,这导致某些实现是不稳定的。ES2019 明确规定,Array.prototype.sort()的默认排序算法必须稳定。这个规定已经做到了,现在 JavaScript 各个主要实现的默认排序算法都是稳定的。
构造 Date 对象的字符串格式问题
JavaScript 构造 Date 对象时要传的字符串标准格式为 yyyy/MM/dd HH:mm:ss,正常情况下日期字符串的格式为 yyyy-MM-dd HH:mm:ss ,无法直接使用(Chrome 可以,IE 不可以)。需要字符串替换后使用 replace(/-/g,"/")。